The Half-Life of Tooling: A Startup Note on the CPU Convergence
I have been using Hermes with Codex.
Each kanban card takes 15 to 18 minutes to complete. I am neurotic when it comes to code quality, so I let it run.
While I waited, I had ARM and Intel charts open in another tab.
That is where this piece comes from.
The market figured it out first
The names that should be losing the AI trade are winning it.
Some receipts from the last few months:
- ARM: up roughly 84% YTD
- Intel: up roughly 240% YTD, up 500% in twelve months
- AMD: up roughly 112% YTD
- Nvidia: up roughly 15% YTD
Mizuho called it “a changing of the guard in AI.” That is the right phrase.
For three years the AI infrastructure narrative was simple: more GPUs, faster GPUs, bigger GPU clusters. The model was the constraint. Everything else was plumbing.
That narrative has cracked.
Intel surged 30% in a single day on Q1 earnings, with the CEO openly saying CPU-to-GPU ratios are moving from 1:8 toward parity. ARM’s data center royalties more than doubled year-over-year for the third quarter in a row. AMD’s Lisa Su told investors the server CPU TAM is now projected to grow over 35% annually to more than $120 billion by 2030. She doubled that forecast in six months.
The market priced in something the AI press took a year longer to admit.
What I converged on watching Hermes
Watching a coding agent run is a strange exercise. You stop looking at the output log and just notice the latency.
Most of it is not the model.
The model does its thing in a couple of seconds. Then the rest happens somewhere I cannot see. The agent spins up a sandbox to try the code. Reads files. Parses JSON. Decides whether to retry. Calls another tool. Waits on a vector lookup. Hands off to a sub-agent. Writes back to memory.
Each step is tiny. Each task has thousands of them. None of them parallelize on a GPU.
This connects to something I wrote about after ICLR: the model is no longer the whole product. The system around the model is.
And that system runs on a CPU.
Put those two thoughts together, and the ARM and Intel charts stop being a market quirk. They are pricing in a hardware truth that has been visible from inside the agent loop for months.
What “the system runs on a CPU” actually means
Arm’s own framing is the cleanest version of this. In its FY26 earnings letter, the company said data centers will need 4x current CPU capacity per gigawatt as agentic AI scales. Multi-agent systems push token generation up by roughly 15x per user. Across most agentic workloads, 50% to 90% of end-to-end latency happens on the CPU side, between the inferences.
That is not a marketing pivot. That is a budget reality.
GPUs do inference. CPUs do everything between the inferences. In an agentic system, “everything between the inferences” is most of the wall-clock time.
This is why Hermes takes 15 minutes. This is why ARM is up 84%. It is the same fact, observed from two different chairs.
How this gets resolved
Two phases.
Phase 1: more CPUs, better CPUs.
This is what the market is already trading. ARM AGI CPU (136 Neoverse V3 cores, custom silicon, $2 billion in FY27/FY28 demand from Meta, OpenAI, Cerebras, and others). Intel’s data center segment growing 22% on agentic demand. AMD EPYC Venice with 256 Zen 6 cores. NVIDIA’s own Vera CPU, Arm-based, paired with Rubin GPUs. Google Axion, Microsoft Cobalt, Amazon Graviton at $20B+ run rate.
If the bottleneck is CPU orchestration in a fixed power envelope, then for the next 12 to 24 months the answer is to throw better general-purpose CPUs at it. That is the trade the market is making right now.
Phase 2: custom silicon for the hot parts.
Once the general-purpose CPU push has done what it can, the next question becomes which parts of the agent loop are stable enough and hot enough to burn into a chip.
My bet on three:
- Retrieval and reranking. A memory-attached accelerator does roughly 20x more queries per watt at scale. Academic prototypes (ANNA, Falcon, Chameleon) have already shown the ceiling. This is the only one of the three with a real standalone business.
- Sandbox creation. Every tool call needs a fresh isolated environment. Today that is around 100ms of overhead per call. Hardware-enforced capability switching, the CHERI line of work, can take it to microseconds. Across one agent task, seconds saved.
- Constrained output. The part that forces the model to emit valid JSON or code. Small. Hot. Regular. Better licensed as IP than sold as a chip.
These do not need to ship as three separate products. They get absorbed.
Why the AGI chip eats this anyway
Hardware trends usually start as accelerator cards and end up as IP blocks on a single SoC. GPUs absorbed dedicated rasterizers. SoCs absorbed image signal processors, video codecs, NPUs. The TPU started as a side project and is now central to Google’s compute.
The same will happen to agent-loop silicon. The retrieval engine, the sandbox MMU extensions, and the constrained-decode FSM are all small enough in die area that the next generation of AGI chip — whoever ships it, ARM or Nvidia or Meta or someone we have not heard of yet — pulls them onto the same package as the model accelerator. Probably alongside an HBM tier sized for the KV cache and the vector store.
That is the long shape:
CPU is the bottleneck → custom accelerators emerge → accelerators get pulled into a single die → the agent loop becomes a hardware-native primitive
When that happens, “running an agent” stops being a fan-out of services across CPU, GPU, and storage. It becomes a single chip doing all of it.
What this means for startups
This is the part that matters most if you are building.
A large fraction of the current agentic startup landscape is tooling. Tools the agent calls. Wrappers around agents. Integrations the agent invokes. The entire “MCP server for X” surface area.
That category gets eaten in two ways.
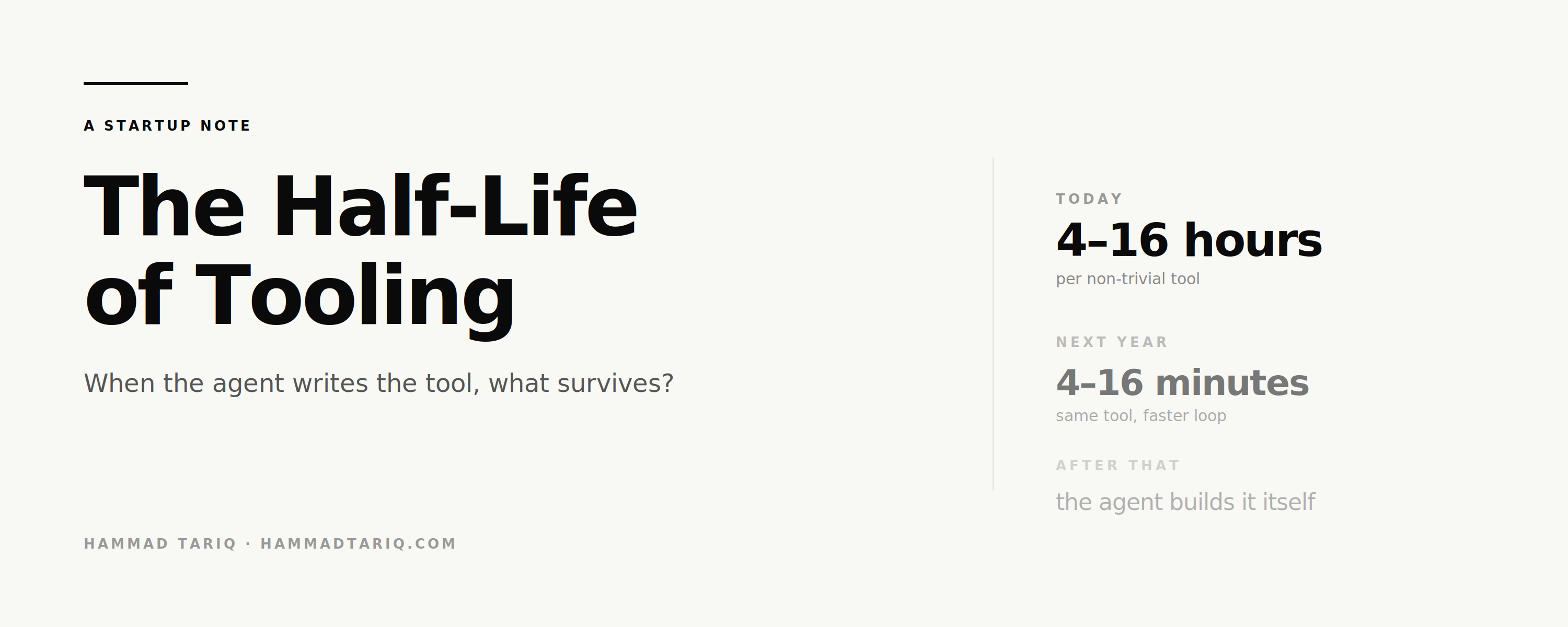
First, by the speed of the loop itself.
If a coding agent today takes 4 to 16 hours to build a moderately complex tool, the same tool gets built in 4 to 16 minutes within 12 to 18 months. CPU speedup alone does not deliver that. Stack the CPU work with better base models, parallel sub-agents, cached patterns from prior runs, and improved harnesses, and 50x to 100x on end-to-end task time is realistic. The agent loop compounds the way a compiler pipeline compounds.
Second, by the agent itself choosing whether to build or reuse.
Once an agent can write a tool faster than a human can ship the integration, the agent writes the tool. The decision to call your SaaS becomes a build-vs-buy decision the agent makes in milliseconds. If your moat is “we built the connector to X,” the half-life of that moat shortens every quarter.
The harder, longer-lived layer is the core AI work:
- the model itself
- the harness around the model
- the memory and state layer
- the evaluation and reward signals
- the policy and identity layer (this is where I have been spending time with Attach and OpenBotAuth)
- the data that feeds it
- the infrastructure that the model cannot generate on its own
These are the parts that do not fall to faster CPU loops. They are also the parts most agentic startups are not focused on.
I have been saying versions of this for a while, in the policy-as-code piece and the memory piece. The CPU and silicon angle makes it sharper. The faster the agent loop gets, the more value moves to the parts the agent cannot generate by itself.
What I am watching
A few signals over the next two to four quarters:
- Whether ARM’s AGI CPU ships on time and lands at hyperscalers. Supply is the bottleneck on the bottleneck. Reuters flagged this on the Q4 call.
- Whether a sovereign or regional cloud announces a near-memory retrieval accelerator. Gulf, Singapore, EU. These are the buyers who care about watts-per-query and cannot wait for the hyperscalers to build internally.
- Whether a CHERI-style capability extension lands in a commercial ARM Neoverse core. That is the path for sandbox isolation to move from research to production silicon.
- Whether anyone bundles constrained-decode acceleration into an inference appliance. Groq, Cerebras, SambaNova are the natural homes.
The shape of the next bottleneck
The last AI hardware war was about training models.
The next one is about running agents.
The chips look different. The companies winning look different. And the startups that survive will be the ones building the parts the agent cannot build on its own.
That is the convergence I saw watching Hermes work through a kanban card with ARM and Intel charts open in another tab. Same picture, two screens.
Find me at @hammadtariq if you are thinking about this.
Article drafted in conversation with Claude.